

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- 커널
- mr 100
- hardware hakcing
- physmap
- Kernel
- UART
- exit handler overwrite
- 공유기
- e
- Slab free list poisoning
- tp link
- System Management Mode
- protection ring
- Pwnable
- linux ring 권한 구조
- SMM
- exploit
- memory
- kernel exploit
- mips
- Router
- 익스플로잇
- ROP
- openwrt
- fini array
- tl mr 100
- 라우터
- Cross-cache attack
- Today
- Total
haehet
[Linux kernel] 메모리 관리 3편: Slab Allocator 본문
이번 글에서는 kernel exploit에서 기본지식이 되는 Slub allocator에 대해서 정리해보겠다.(틀린 내용이 있을 수도 있으니 양해 부탁드립니다..)
1. Slab allocator란?
Slab allocator는 커널 영역의 메모리를 효율적으로 관리하기 메모리 할당기이다. 기존의 buddy system을 통한 메모리 관리는 2^n 단위로만 메모리를 할당 해 주기 때문에 내부 단편화가 생길 수 있다는 단점이 있었다. 이를 해결하기 위해 Slab allocator가 등장하였다.

시간이 흐르면서(그리고 수많은 커널 버전을 거치면서) 리눅스의 slab allocator는 발전했고 구조도 상당히 많이 바뀌었다. 현재까지 서로 다른 구현이 세 가지 존재한다. 이 글에서는 Slub allocator에 대해 설명할 것이며 편의상 Slab allocator라 지칭하겠다.
● SLAB allocator: SLOB 할당기를 개선한 방식으로 캐시 친화적(cache-friendly)이 되도록 설계되었다. 더 좋은 성능의 SLUB allocator가 나오고 난 이후로 쓰이지 않는다.
● SLUB allocator: 대부분의 kernel 배포 버전에서 쓰이는 allocator이다. slab에 비해 메모리 지역성이 향상되었으며 slab에 비해 관리가 단순하다.
● SLOB allocator: Solaris OS에서 구현된 슬랩 할당기이다. 현재는 메모리가 부족한 임베디드 시스템에서 사용되며 매우 작은 메모리 청크를 할당할 때 성능이 좋다. first-fit(최초 적합) 할당 알고리즘을 기반으로 한다.
2. Slab allocator의 구조 및 용어
Slab allocator는 커널이 자주 할당·해제하는 동일 크기/동일 타입의 객체에 대해 그 객체 전용 캐시(kmem_cache)를 만들고 페이지 단위로 확보한 메모리(slabs)를 객체 크기로 잘라 미리 준비해 둔 뒤 할당 시에는 일반적인 페이지 할당 대신 캐시에서 객체를 재사용하게 함으로써 할당/해제 오버헤드와 단편화를 줄인다.
슬랩 할당자에서 주로 나오는 용어에 대한 정의는 다음과 같다.
● Slab page: slab object 할당을 위해 Buddy system에서 할당받은 order-n 단위의 page를 말한다.
● Slab object: slab cache에서 관리하는 object이다.
● Slab cache: 특정 타입/크기의 커널 객체를 위한 전용 메모리 풀로 slab을 확보해 객체를 쪼개고 freelist로 재사용을 관리한다.
위 설명을 그림으로 표현하면 다음과 같다.

slab cache는 위와 같이 할당 받은 slab page가 모여서 구성된다.

slab allocator은 크게 두 가지 종류의 캐시를 제공한다.
1. Dedicated(전용) 캐시: 커널에서 자주 사용되는 객체(예: mm_struct, vm_area_struct 등)를 위해 커널이 직접 생성한 전용 캐시다. 이 캐시에서 할당되는 구조체는 초기화되며 해제된 뒤에도 초기화된 상태가 유지되므로 다음에 같은 구조체를 다시 할당할 때 더 빠르게 할당할 수 있다.
2. Generic(일반) 캐시 (size-N 및 size-N(DMA)): 범용 캐시로 대부분의 경우 크기가 2의 거듭제곱에 해당하는 size-class로 구성된다.
이러한 구분은 proc file system에서 확인 가능하다.
~ # cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_>
vm_area_struct 80 80 200 20 1 : tunables 0 0 0 : slabdata 4 4 0
mm_struct 120 120 1088 30 8 : tunables 0 0 0 : slabdata 4 4 0
files_cache 92 92 704 23 4 : tunables 0 0 0 : slabdata 4 4 0
signal_cache 180 180 1088 30 8 : tunables 0 0 0 : slabdata 6 6 0
sighand_cache 105 105 2112 15 8 : tunables 0 0 0 : slabdata 7 7 0
task_struct 128 128 3776 8 8 : tunables 0 0 0 : slabdata 16 16 0
cred_jar 231 231 192 21 1 : tunables 0 0 0 : slabdata 11 11 0
dma-kmalloc-512 16 16 512 16 2 : tunables 0 0 0 : slabdata 1 1 0
dma-kmalloc-256 0 0 256 16 1 : tunables 0 0 0 : slabdata 0 0 0
dma-kmalloc-128 0 0 128 32 1 : tunables 0 0 0 : slabdata 0 0 0
dma-kmalloc-64 0 0 64 64 1 : tunables 0 0 0 : slabdata 0 0 0
dma-kmalloc-32 0 0 32 128 1 : tunables 0 0 0 : slabdata 0 0 0
dma-kmalloc-16 0 0 16 256 1 : tunables 0 0 0 : slabdata 0 0 0
dma-kmalloc-8 0 0 8 512 1 : tunables 0 0 0 : slabdata 0 0 0
kmalloc-512 304 304 512 16 2 : tunables 0 0 0 : slabdata 19 19 0
kmalloc-256 176 176 256 16 1 : tunables 0 0 0 : slabdata 11 11 0
kmalloc-192 798 798 192 21 1 : tunables 0 0 0 : slabdata 38 38 0
kmalloc-128 448 448 128 32 1 : tunables 0 0 0 : slabdata 14 14 0
kmalloc-96 798 798 96 42 1 : tunables 0 0 0 : slabdata 19 19 0
kmalloc-64 2560 2560 64 64 1 : tunables 0 0 0 : slabdata 40 40 0
kmalloc-32 3200 3200 32 128 1 : tunables 0 0 0 : slabdata 25 25 0
kmalloc-16 1792 1792 16 256 1 : tunables 0 0 0 : slabdata 7 7 0
kmalloc-8 2048 2048 8 512 1 : tunables 0 0 0 : slabdata 4 4 0
3. Slab cache의 구조
위에서 설명한 slab cache는 kmem_cache 구조체를 통해 표현된다.
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
void (*ctor)(void *);
int inuse; /* Offset to metadata */
int align; /* Alignment */
const char *name; /* Name (only for display!) */
...
struct kmem_cache_node *node[MAX_NUMNODES];
};위 캐시는 또 2개의 형태로 나뉜다.
● kmem_cache_cpu __percpu *cpu_slab: 빠른 할당을 위해 CPU별로 슬랩캐시를 관리하는 구조체이다.
● kmem_cache_node *node[MAX_NUMNODES]: NUMA 구조에서 슬랩 페이지들을 노드별로 관리하기 위한 구조체이다.

kmem_cache_cpu 구조체는 다음과 같다.
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
4. Slab object allocation
slab object는 5개의 방식(Fast path, Slowpath-1, Slowpath-2, Slowpath-3, Slowpath-4)중 한개로 할당된다.
4.1 Fast path
Fastpath는 가장 빠른 할당방식으로 현재 percpu→freelist에 할당 가능한 object가 있으면 바로 할당해주는 방식이다.

4.2 Slowpath -1
현재 percpu→freelist에 사용할 수 있는 object가 없을 경우 Slowpath-1 방식이 실행된다. percpu →page →freelist에 들어있는 object를 percpu→freelist로 올리고 fastpath로 돌아간다.

4.3 Slowpath-2
slowpath-1에서 percpu →page에 free된 object가 없는 경우 실행된다. percpu→partial에 있는 slab page를 percpu→page로 올리고 slab page 내부 object들을 percpu→freelist로 이동시킨다.
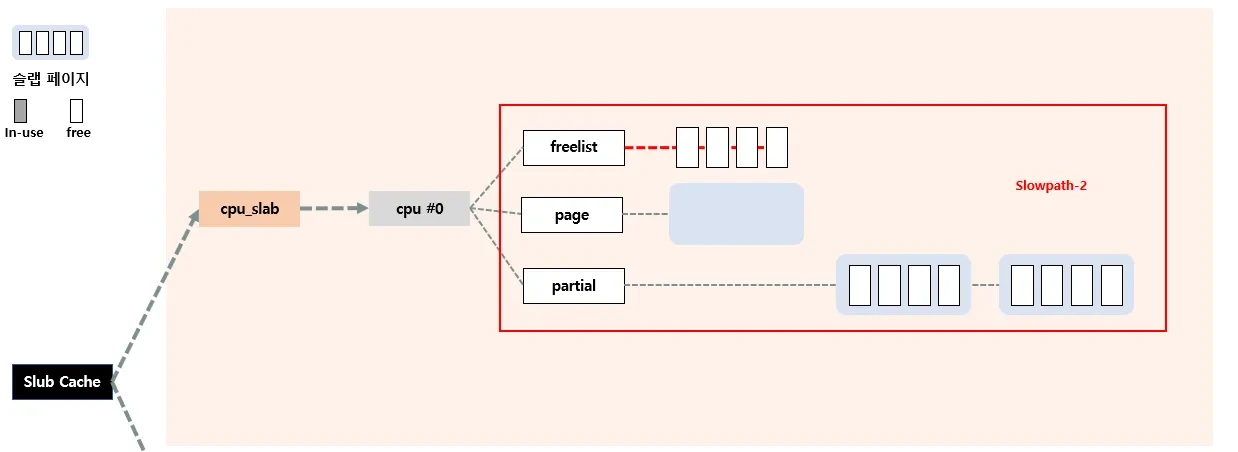
4.4 slow path-3
percpu→partial에 할당 가능한 object가 없는 경우 실행된다. node → partial에 들어있는 첫 슬랩 페이지를 percpu→page로 올린다.

4.5 slowpath-4
위 과정이 모두 실패한 경우로 buddy system에서 새로운 slab page를 할당 받는다. 그리고 percpu→page, percpu→freelist에 슬랩 오브젝트를 옮긴다.

전체 과정을 보면 다음과 같다.

5. Slab object free
해제 과정은 할당과정과 매우 유사하게 이루어진다.
5.1 fast path
현재 반환하는 object가 현재 cpu의 percpu→page에서 관리중이였다면 바로 percpu→freelist에 추가한다.

5.2 slow path
현재 반환하는 object가 현재 cpu의 percpu→page에서 관리중이 아니였다면 다음 3가지 경우로 나뉜다.
1. percpu→partial의 슬랩 페이지 혹은 다른 CPU의 percpu→page에 반환
● 1. 현재 cpu의 percpu→partial에서 관리

● 2.다른 cpu의 page에서 관리
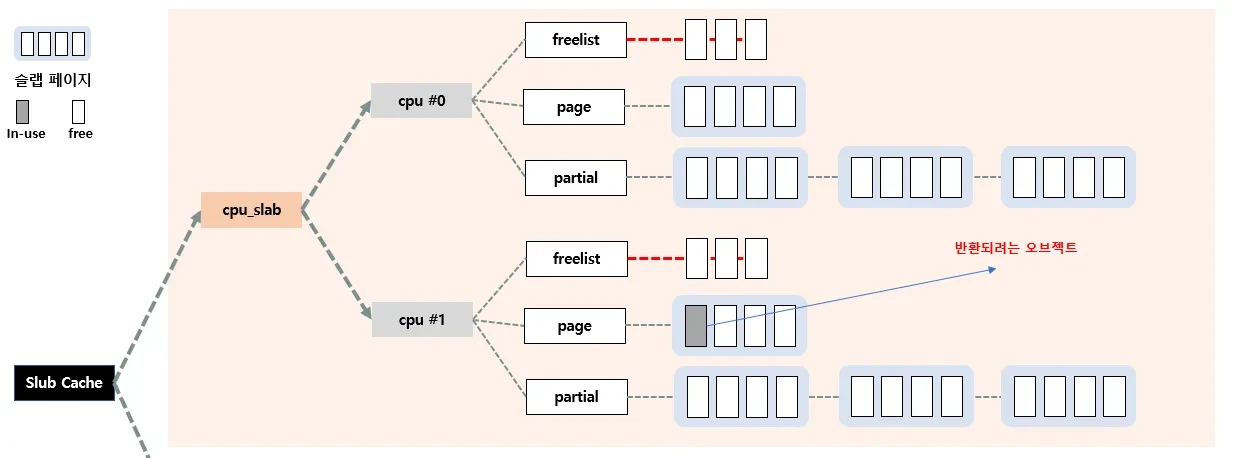
● 3. 다른 cpu의 partial에서 관리

2. node→partial의 슬랩페이지에 반환

3. Buddy system으로 반환
percpu→partial에서 관리할 수 있는 slab page가 꽉찬 경우 모든 slab object가 free 상태인 경우 buddy system을 통해 slab page를 반환 시킨다. 이 과정을 이용하면 UAF등의 primitive를 다른 slab cache로 옮길 수 있는 cross cache attack이 가능해진다.

6. Slab mitigations
kernel은 다음과 같은 보안 기법을 통해 slab 내부에서 kernel exploit을 어렵게 만든다.
6.1 Freelist randomization
freelist 내부 객체들의 순서를 랜덤화 시켜서 객체의 할당을 예측하기 어렵게 만든다.
#ifdef CONFIG_SLAB_FREELIST_RANDOM
/* Pre-initialize the random sequence cache */
static int init_cache_random_seq(struct kmem_cache *s)
{
unsigned int count = oo_objects(s->oo);
int err;
/* Bailout if already initialised */
if (s->random_seq)
return 0;
err = cache_random_seq_create(s, count, GFP_KERNEL);
if (err) {
pr_err("SLUB: Unable to initialize free list for %s\n",
s->name);
return err;
}
/* Transform to an offset on the set of pages */
if (s->random_seq) {
unsigned int i;
for (i = 0; i < count; i++)
s->random_seq[i] *= s->size;
}
return 0;
}
/* Get the next entry on the pre-computed freelist randomized */
static void *next_freelist_entry(struct kmem_cache *s, struct slab *slab,
unsigned long *pos, void *start,
unsigned long page_limit,
unsigned long freelist_count)
{
unsigned int idx;
/*
* If the target page allocation failed, the number of objects on the
* page might be smaller than the usual size defined by the cache.
*/
do {
idx = s->random_seq[*pos];
*pos += 1;
if (*pos >= freelist_count)
*pos = 0;
} while (unlikely(idx >= page_limit));
return (char *)start + idx;
}
6.2 Slab freelist hardened
freelist는 Single linked list 형태로 LIFO구조를 가진다. 이때 Slab freelist hardened는 next pointer에 대한 암호화를 진행한다.
static inline freeptr_t freelist_ptr_encode(const struct kmem_cache *s,
void *ptr, unsigned long ptr_addr)
{
unsigned long encoded;
#ifdef CONFIG_SLAB_FREELIST_HARDENED
encoded = (unsigned long)ptr ^ s->random ^ swab(ptr_addr);
#else
encoded = (unsigned long)ptr;
#endif
return (freeptr_t){.v = encoded};
}
또한 해당 config가 켜져있을 경우 연속한 DFB를 감지한다.
static inline void set_freepointer(struct kmem_cache *s, void *object, void *fp)
{
unsigned long freeptr_addr = (unsigned long)object + s->offset;
#ifdef CONFIG_SLAB_FREELIST_HARDENED
BUG_ON(object == fp); /* naive detection of double free or corruption */
#endif
freeptr_addr = (unsigned long)kasan_reset_tag((void *)freeptr_addr);
*(freeptr_t *)freeptr_addr = freelist_ptr_encode(s, fp, freeptr_addr);
}
reference:
https://hammertux.github.io/slab-allocator
https://jeongzero.oopy.io/132fed8f-5cfd-4f43-990c-61584744b4d0#4d29d2de-ef50-4600-bd88-fcef5d075874
http://jake.dothome.co.kr/slub/#comment-304534
https://www.usenix.org/system/files/usenixsecurity23-lee-yoochan.pdf
https://www.slideshare.net/slideshow/slab-allocator-in-linux-kernel/253184071#10
https://sam4k.com/linternals-memory-allocators-0x02/#struct-kmemcache
'Linux kernel' 카테고리의 다른 글
| [Linux kernel] Slab free list poisoning (0) | 2026.01.25 |
|---|---|
| [Linux kernel] Cross-cache attack (0) | 2026.01.23 |
| [Linux Kernel] 메모리 관리 2편: Page Allocator (PCP & Buddy System) (0) | 2026.01.09 |
| [Linux Kernel] 메모리 관리 1편: TLB와 Page Table Walk: Multi Level paging 동작 원리 (0) | 2026.01.08 |
| [Linux kernel] 링 권한 구조와 SMM(System Management Mode) (0) | 2026.01.06 |